Clustering overview
While they're different services, the clustering and caching systems interoperate. In fact, an application cluster requires the presence of a separate cache server for caching data for use by all application server nodes in the cluster.
For information on installing the application on a cluster, see Setting up cluster.
Parts of clustering system
- Application servers
- In the middle-tier, multiple application servers are set up and the clustering feature is enabled. Caches between the application instances are automatically synchronized. If a particular application server fails, the load balancer detects this and removes the server from the cluster.
- Cache server
- On a separate machine from application servers is a cache server that is available to all application server nodes in the cluster. Note that you can't create a cluster without declaring the address of a cache server.
- Database server
- All instances in a cluster share the same database.
- Load balancer
- Between users and the application servers is a load-balancing device. The device may be hardware- or software-based. Every user has a session (represented by a unique cookie value) that allows stateful data to be maintained while they are using the application. Each session is created on a particular application server. The load balancer must be session-aware, meaning that it inspects the cookie value and always sends a given user's requests to the same application server during a given session. Without session-aware load balancing, the load balancer could send requests to any application server in the cluster, scrambling results for a given user.
Typical cluster configuration
A typical cluster configuration is shown in the diagram below. Note that the database server and cache server are separate nodes, but not part of the cluster.
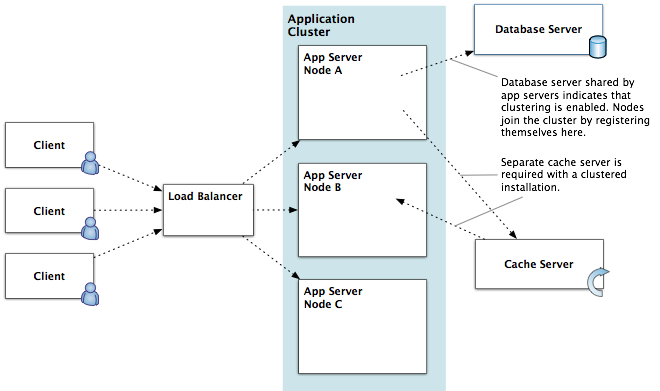
The existence of a cluster is defined in the database, which stores the TCP endpoint for each node in the cluster. A node knows it's supposed to be in a cluster because the database it is using shows that clustering is enabled. Nodes in a cluster use the application database to register their presence and locate other nodes. Here's how that works at startup:
- When an application server machine starts up, it checks the database to discover the TCP endpoint (IP address and port) it should bind to.
- If the node can't find its TCP endpoint in the database (because this is the first time is has started and tried to join a cluster, for example), it looks for the first non-loopback local address it can use. It tries to bind to a default port (7800). If it fails, it scans up to port 7850 until it finds a port it can bind to. If this fails, the node doesn't join the cluster.
- Having established an endpoint for itself, the node notes the other node addresses it found in the database.
- The node joins the cluster.
Clustering best practices
Here are a few best practice suggestions for clustered installations.
- Ensure that the number of nodes in your cluster is greater than what you'll need to handle the load you're getting. For example, if you're at capacity with three nodes, then the cluster will fail when one of those nodes goes down. Provision excess capacity so that your deployment can tolerate a node's failure.
- If you have document conversion enabled, and one of the machines is faster than the others, start that one first.